

本文从数据处理、卷积方式设计、架构设计、激活函数选取原则、优化器选择等方向探讨如何设计性能优秀的CNN模型,并记录优化指标的侧重点。
同时根据工程经验阐述,可以从哪几个方面优化CNN模型准确率、训练速度、内存消耗三个指标。并出提出其优化的可能方向。
该文仅用于记录学习和探讨问题,提供的优化思路如有不对,可以一起探讨。
CNN 解决了什么问题?
在 CNN 出现之前,图像识别对于机器来说是一个难题,原因如下:
- 图像需要处理的数据量太大,导致成本很高,效率很低
- 图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高
CNN(卷积神经网络 ) 的核心思想是将复杂问题简化,拥有大量参数的源数据经过卷积映射到特征空间后会将维成少量具有核心价值的参数。并且,在大部分场景下,降维并不会影响结果。图像的简单数据化无法保留图像特征,但CNN用类似视觉的方式保留了图像的特征,当图像做翻转,旋转或者变换位置时,它也能有效的识别出来是类似的图像。根据这两大特性完美地解决了图像识别的两个难题。
CNN 的实际应用:
- 图片分类、检索、目标定位检测、目标分割、人脸识别、骨骼识别、药物识别
优化指标
- 准确率
- 速度
- 内存消耗
不同的网络(如VGG、Inception 以及 ResNet 等)在这些指标上有不同的权衡。此外,你还可以修改这些网络结构,例如通过削减某些层、增加某些层、在网络内部使用扩张卷积,或者不同的网络训练技巧。 关于Inception 以及 ResNet等内容可参考如下贴文:
Inception系列和ResNet的成长之路_IT荻的博客-CSDN博客_inception-resnet直接给结果:看重准确率,用超深层的 ResNet;看重速度,用 Inception。
目前AI发展遇到的最大瓶颈之一就是在数据质量上往往不尽人意,如果初始数据不够优质,那模型训练来训练去都是在做一件事情——过拟合。想要得到好的模型训练结果,对数据的质量有很高要求,除去基本的数据清洗处理之外,还可以是用数据增强方法提升数据质量。
增强类型取决于你的应用场景,例如在做人脸识别的适合,照片失焦、照片不清晰、照片角度不对等,可以通过改变光线调整、色彩填充、图片翻转来增强数据。如果你做的是无人驾驶,你可能会遇到各种障碍物或者极端视频场景,所以,以上适合人脸识别的增江手段意义不大。具体如何增强数据可以参考:
aleju/imgaug同时针对class skew(数据偏斜/数据不均衡)的情况,可以采取以下方法:
- 过采样:针对数据很小的情况,对训练样本中数量不足的类别进行重复采样,这样有助于样本分布的均衡化。当可用数据较少的时候这个方法最能奏效。
- 降采样:针对数据量很大的情况,对数据先进行聚类,再将大的簇进行随机欠采样或者小的簇进行数据生成
- SMOTE算法:对数据进行采用的过程中通过相似性同时生成并插样“少数类别数据”
- 集成学习:先对多数类别进行随机的欠采样,并结合boosting算法进行集成学习
- 类别权重:损失函数中使用类别权重:样本不足的类别赋予更高权重
- 改变学习方法:把监督学习变为无监督学习,舍弃掉标签把问题转化为一个无监督问题,如异常检测
数据加载器批训练也是不错的方法之一,针对batch的小大和batch数量如何去选择,可以参考优秀答主:
夕小瑶:训练神经网络时如何确定batch size?以下列举一些能够在没有太多的准确率损失的情况下加速 CNN 的运行,并减少内存消耗的方法。注意:所有方法都可以很容易地应用到任何一类CNN(卷积神经网络)的设计中。
- MobileNets(https://arxiv.org/pdf/1801.04381.pdf)使用深度分离的卷积来极大地减少运算和内存的消耗,同时仅牺牲 1% 到 5% 的准确率,准确率的牺牲程度取决于你想要获得的计算节约。
- XNOR-Net(https://arxiv.org/pdf/1603.05279.pdf)使用二进制卷积,意味着,卷积运算只涉及两个可能的数值:0 或者 1。通过这种设计,网络可以具有较高程度的稀疏性,易于被压缩而不消耗太多内存。
- ShuffleNet(https://arxiv.org/pdf/1707.01083.pdf)使用点组卷积和通道随机化来极大地减少计算代价,同时还能维持比 MobileNets 高的准确率。事实上,它们可以在超过 10 倍的运算速度下达到早期最先进的分类 CNN 的准确率。
- Network Pruning(https://arxiv.org/pdf/1605.06431.pdf)删除 CNN 的部分权重的技术,而且有希望不降低准确率。为了保持准确率,被删除的部分应该对最终结果没有大的影响。链接中的论文展示了使用 ResNets 可以轻易地做到这一点。
卷积核大小
通常来说,更大的卷积核准确率越高,但训练速度会变慢消耗内存也会更多,并且较大的卷积核会导致网络泛化能力很差,ResNet 和VGGNet 都相当全面的诠释了这一点
DilatedConvolution(扩张卷积)
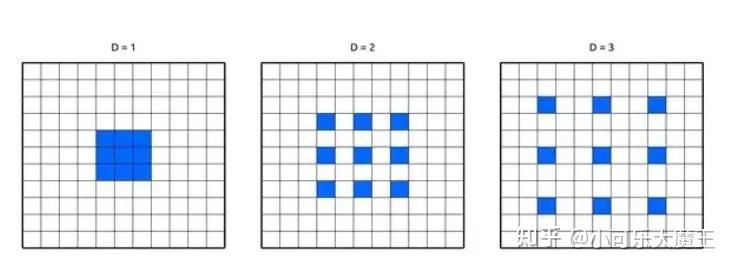
在卷积核的权重之间使用空格。使得网络不用增加参数量就能够扩展感受野,意味着没有增加内存消耗。该方法已经被证明可以在微小的速度权衡下就能增加网络准确率。
因为GPU是并行处理的,增加宽度相对于增加深度对GPU更加友好,许多研究也表明加宽网络比加深网络也更加容易训练。针对如何选择合适的神经网络宽度、深度附上如下详解:
宽度
宽度使得每一层学习到更加丰富的特征,以人脸识别为例,可以学到不同方向,不同频率的纹理特征,对于一个模型来说,浅层的特征非常重要,因此网络浅层的宽度是一个非常敏感的系数。宽度带来的计算量是平方级增长的。同时宽度带来的好处受制于边际效应,增加的每层的宽度越大,通过增加层宽而带来的模型性能提升也会越少。
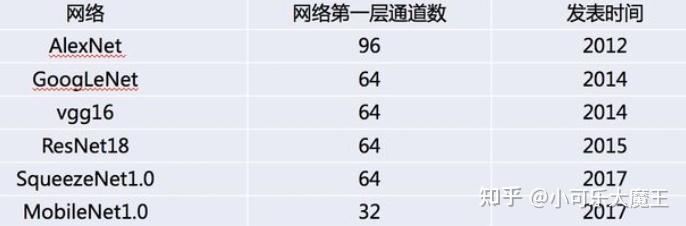
根据经典的一些深度学习网络模型的发展趋势来看,学术界提出的优秀模型,层宽都在逐渐减小,如下图所示
深度
网络更深带来的一个非常大的好处,就是逐层的抽象,不断精炼提取知识,如第一层学习到了边缘,第二层学习到了简单的形状,第三层开始学习到了目标的形状,更深的网络层能学习到更加复杂的表达。
选择合适的网络深度也是设计的重要思想之一,通常增加更多地层会提升准确率,同时会牺牲一些速度和内存。但是受制于边际效应,增加的层越多,通过增加每一层而带来的准确率提升将越少。
根据工程经验,通常使用 ReLU 会在开始的时立即得到一些好的结果,但如果当ReLU得不到好的结果的适合,可以换成Sigmoid函数,如果还是不行则调整模型其它的部分,以尝试对准确率做提升。都得不到好结果的情况下,可以试着使用ELU、PReLU 、Sigmoid或者LeakyReLU等激活函数。
应用于图片分类问题的简单CNN,使用不同优化器的训练增速效果如下:

根据工程经验,优化器的选择和激活函数一样的思路:从容易到困难不断试错。我习惯使用最简单的SGD优化器,如果得到还不错的结果则对模型进行其他超参数的调优。也可以使用最为高效的Adam开始,切记学习率不要设置太高。甚至可以组合使用,在前面使用快速的优化器设置较低学习效率,在训练的后半程选择较慢的优化器,进行组合优化器。
后续内容待码。。。。。。
 上一篇
上一篇 



