

之前梳理adam优化器相关的材料已经是2020年的时候了,adam是14年挂在arxiv上,15年被ICLR收录。
从14、15年到20年,再到24年,已经走过了十年;从CNN、lstm到BERT,再到大模型,adam还是大家的默认选项。
adam在过去最大的变化是adamw (weight decay)。
对于梯度,按滑动窗口计算一阶动量、二阶动量,再对一阶、二阶动量做偏差修正,更新模型参数。

早期的GD采用全量样本做梯度下降,sgd是随机采样一个batch的数据来做梯度下降。
sgd采样计算得到的梯度,和全量数据上算出的梯度不一致,且波动较大。通过滑动窗口是为了得到更加稳定的梯度,和全量数据上的梯度尽可能接近。
二阶动量主要用来解决稀疏梯度的问题。例如nlp里面的罕见词,当罕见词出现在batch内的时候,需要适当增加更新的幅度,而常见词可以更新的幅度小一些。
所以二阶动量存的就是该参数是否经常更新。
一段有趣的历史,BERT官方的代码库里抛弃了偏差修正:https://github.com/google-research/bert/blob/master/optimization.py#L137
当时还有论文专门讨论了这个问题: https://arxiv.org/pdf/2006.05987.pdf
偏差修正的影响:
不做修正,会使得一阶、二阶动量偏小。
常见参数下 ,会使得更新项偏大。在微调时,容易抵消warmup的影响。
BERT为啥可以不用偏差修正?
https://github.com/google-research/bert/issues/153
分两种情况看,一种是预训练,预训练的更新步数多;偏差主要是前面的步数影响大,常见参数 下,几千步之后就没啥影响了。所以在预训练的时候,对模型效果的影响就变的微乎其微了。
另一种是微调的时候,BERT作者也说了:
This was mostly an oversight, but doesn't really matter when using a reasonable learning rate warmup.
adam和l2正则不兼容
l2正则做的事情,是对参数做衰减,越大的参数减掉的越大。
这个会跟adam的二阶动量相冲突,大的参数,那他的二阶动量就会比较大,实际adam更新项比较小。adam的二阶动量实际抵消了l2正则。
adamw将l2正则的loss从总的loss中拿了出来,算梯度的时候不算l2正则,下图紫色部分。
只在更新参数的时候才生效,下图绿色部分。
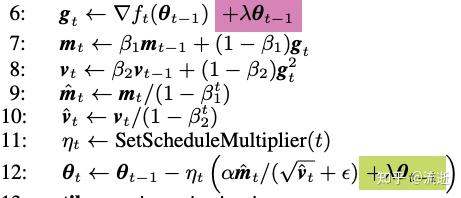
这样的话,l2正则的梯度便不会受到adam二阶动量影响了。
adam方法存了两阶的动量,需要额外占用两份模型大小的显存。如果实在缺显存可以换其他优化器,例如sgd+momentum。
 上一篇
上一篇 



