

初始值通常设置在1e-3, 在学习过程中随着时间降低学习率通常很有用, 以下的学习率衰减方式适用于使用一阶动量的优化算法.
降低学习率的方式有:
-
递减step decay
每几个epoch降低一次,如每5次降低一半,或每20次降低0.1,视情况而定.可以通过尝试不同的固定的学习率对验证集的错误率进行观察来找合适的学习率.
-
指数下降
\(\alpha=\alpha_0 e^{-k t}\),t 是迭代次数,其它是超参数.
-
1/t下降
\(\alpha=\alpha_0 / (1 + k t )\)
-
cosine下降
\(\alpha=\alpha_0 imes (1 + \cos(\pi imes t / T)) / 2\), T 是总迭代次数. 与指数下降类似,但曲线不同. 是 SGDR decay 方法的非重启版本(重启指的是周期性重置学习率).
实际中step decay更常用一些,因为参数更容易解释,更直观. 设置较小的递减速率,训练更长的时间.
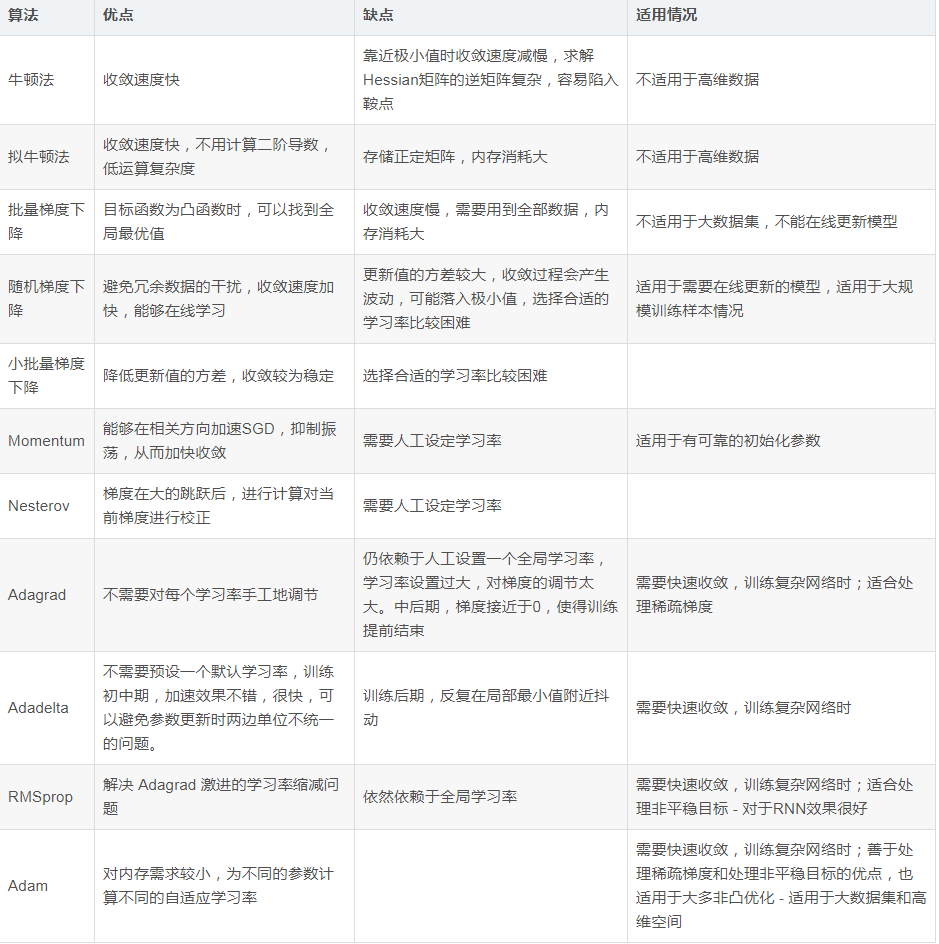
深度学习优化算法经历了 SGD -> SGDM -> NAG ->AdaGrad -> AdaDelta -> Adam -> Nadam 这样的发展历程。
用一个框架来梳理所有的优化算法,做一个更加高屋建瓴的对比。
首先定义:待优化参数: w ,目标函数: f(w) ,初始学习率 \(\alpha\)。
而后,开始进行迭代优化。在每个 epoch t:
- 计算目标函数关于当前参数的梯度: \(g_t= abla f(w_t)\)
- 根据历史梯度计算一阶动量和二阶动量:\(m_t=\phi(g_1, g_2, \cdots, g_t); V_t=\psi(g_1, g_2, \cdots, g_t)\),
- 计算当前时刻的下降梯度: \(\eta_t=\alpha \cdot m_t / \sqrt{V_t}\)
- 根据下降梯度进行更新:\(w_{t+1}=w_t - \eta_t\)
掌握了这个框架,你可以轻轻松松设计自己的优化算法。
那对SGD来说就是只用一阶动量计算下降梯度,缺点是可能停留在局部最优点;
为解决上面问题,提出了momentum,也就是在计算梯度下降方向时不仅由当前点梯度决定,也有此前累积下降方向决定;
AdaGrad从名字应该可以看出来是自适应和梯度英文的缩写,标志使用二阶动量以及自适应学习率,二阶动量则为迄今为止所有梯度值的平方和;
AdaDelta 则是对AdaGrad的改进,不累积全部历史梯度,而只关注过去一段时间窗口(Delta)的下降梯度;
Adam——Adaptive + Momentum(一阶动量和二阶动量进行结合).
(vanilla作为形容词,意思是普通的,平凡的)
沿着负梯度方向更新参数以最小化损失.
下降速度慢,容易停留在局部点.
SGD with momentum,在SGD基础上引入了一阶动量:
为避免每次梯度更新时都独立计算梯度,导致梯度方向持续变化,Momentum 将上一轮的梯度值加入到当前梯度的计算中。
也就是说,t时刻的下降方向,不仅由当前点的梯度方向决定,而且由此前累积的下降方向决定。其中\(\beta_1\in [0,1)\), \(\beta_1\) 的经验值为0.9,这就意味着下降方向主要是此前累积的下降方向,并略微偏向当前时刻的下降方向。对\(\beta_1\)进行调优可以从0.5作为初始值,再依次尝试[0.9, 0.95, 0.99],(模拟退火的过程).
形象的解释为:重力作用使其震荡的幅度减小,加速下降。
动量法使用了指数加权移动平均的思想。它将过去时间步的梯度做了加权平均,且权重按时间步指数衰减。 即\(m_t ← \beta_1 m_{t?1} + (1 ? \beta_1)({\alpha_t\over 1?\beta_1}g_t)\).
动量法使得相邻时间步的自变量更新在方向上更加一致,从而降低大梯度值更新时发散的可能。
比上面的momentum更新方式表现的更好一些,改进之处在于将计算梯度的位置x转移到了动量更新之后:
效果更好,
进一步阅读:
- Advances in optimizing Recurrent Networks by Yoshua Bengio, Section 3.5.
- Ilya Sutskever's thesis (pdf) contains a longer exposition of the topic in section 7.2
其中⊙是按元素相乘。这里开方、除法和乘法的运算都是按元素运算的。这些按元素运算使得目标函数自变量中每个元素都分别拥有自己的学习率。
AdaGrad 是 Adaptive Gradient 的缩写,为解决 GD 中固定学习率带来的不同参数间收敛速度不一致的弊端,AdaGrad 为每个参数赋予独立的学习率。计算梯度后,梯度较大的参数获得的学习率较低(由二阶动量控制),反之亦然。
对于经常更新的参数,我们已经积累了大量关于它的知识,不希望被单个样本影响太大,希望学习速率慢一些;对于偶尔更新的参数,我们了解的信息太少,希望能从每个偶然出现的样本身上多学一些,即学习速率大一些。
怎么样去度量历史更新频率呢?那就是二阶动量——该维度上,迄今为止所有梯度值的平方和:
Adagrad更新规则为:
自适应学习率调整,相当于由于一次性移动dx太大而加的惩罚,增加对震荡的阻力。
优点: 无须指定学习率的下降方式(只需指定初始学习率)
缺点: 梯度平方累计, 导致后期学习率极小.随着迭代次数的增大,学习率逐渐降低,直到趋近于0,不再进行学习.
由于AdaGrad单调递减的学习率变化过于激进,我们考虑一个改变二阶动量计算方法的策略:不累积全部历史梯度,而只关注过去一段时间窗口的下降梯度。这也就是AdaDelta名称中Delta的来历。RMSProp是 Root Mean Square propagation 的缩写,是类似的算法。
RMSProp
修改的思路很简单,仅计算过去的W步的梯度的平方和的根(RMS,root mean square)。由于计算固定大小窗口:\(g_i^{-w},\cdots,g_i^{-1}\)的平方和与计算累计指数下降:\(E[(g_i)^2]^s=ρ E[(g_i)^2]^{s-1}+(1-ρ)(g_i^s)^2\)在概念上等价,且计算量更小,其中ρ 是decay或称momentum.
指数移动平均值大约就是过去一段时间的平均值,因此我们用这一方法来计算二阶累积动量:
这种滑动平均的方式类似动量法,因此RMSProp可看作结合了Momentum与AdaGrad:
AdaDelta
AdaDelta算法跟RMSProp算法的不同之处在于使用 \(\sqrt{\Delta x_{t?1}}\) 来替代超参数学习率。
AdaDelta算法没有学习率超参数,它通过使用有关自变量更新量平方的指数加权移动平均的项来替代RMSProp算法中的学习率。
AdaDelta/RMSProp 优势:避免了二阶动量持续累积、导致训练过程提前结束的问题。
Adaptive Moment estimation 结合了一阶动量与二阶动量,在RMSProp的基础上引入一阶动量(在RMSProp中没有完全运用Momentum):
一般的参数设置为 \(\beta_1=0.9, \beta_2=0.999\), 但是初始时的累计梯度很小。例如,当\(β_1=0.9\)时,\(m_ 1=0.1g_1\) 。
设 \(m_0=V_0=0\) ,在时间步 t 有\(m_t=(1 ? β_1 ) \sum_{i=1}^t β_1^{t-i} g_ i\)。将过去各时间步小批量随机梯度的权值相加,得到 \((1 ? β_1 ) \sum_{i=1} ^tβ_1^{t-i}=1 ? β_1 ^t\)。当t较小时,过去各时间步小批量随机梯度权值之和会较小。
为了消除这样的影响,需要做偏差校正。对于任意时间步t, 可以将\(m_ t\) 再除以\(1 ? β_1^t\) ,从而使过去各时间步小批量随机梯度权值之和为1。
Adam算法使用以上偏差修正后的变量,将模型参数中每个元素的学习率通过按元素运算重新调整。参数更新方式变为:
Adam 既为每一个浮点参数自适应性地设置学习率,又将过去的梯度历史纳入考量。由于引入动量,相比于原始SGD参数量翻倍,增加了内存消耗,但因为效果较好在学术界被广泛采用。
Nadam=Nesterov + Adam
按照NAG的步骤:
Adam的扩展,根据最近的损失的振荡情况,调整学习率. 在 Adam 中仅仅调整局部的学习率, 而 Eve 方法还可以调整全局的学习率.
AMSGrad (二阶动量振荡问题)
ICLR 2018 中的一篇文章 on the convergence of adam and beyond 提出了对 Adam 学习率振荡问题的解决方法.
二阶动量是固定时间窗口内的累积,随着时间窗口的变化,遇到的数据可能发生巨变,使得 \(V_t\) 可能会时大时小,不是单调变化。这就可能在训练后期引起学习率的振荡,导致模型无法收敛。
缓解方式: 数值裁剪, 保证二阶动量非递减(类似保序回归):
通过这样修改,就保证了 \(||V_t|| \geq ||V_{t-1}||\) ,从而使得学习率单调递减。
然而这种方式的实验结果却并不是很理想.
在论文 Fixing Weight Decay Regularization in Adam(Decoupled Weight Decay Regularization) 中指出了在当前的绝大多数深度学习库(Caffe/Tensorflow等)中的L2正则化方式的Adam实现并非 weight decay 的形式,并做了对比实验发现 weight decay 的形式在某些实验中比 L2 正则化的方式要好,因此推荐使用权重衰减而不是L2正则。
先来看原始不带动量版本的 SGD 的 weight decay 更新方式, \(d_w\) 表示参数weight decay:
L2正则项是添加在损失函数中的:
可以看到在 SGD 中 weight decay 与L2正则项形式上等价, 但是权重衰减的量并不相等.
加入momentum动量后L2正则项更新方式为:
而如果应用weight decay原始的概念,应当为:
可以看出在L2中由于学习率作用在 weight decay 上, 因此学习率越小权重衰减的量越小。在自适应学习率的 Adam 优化算法中权重的梯度越大, 自适应的学习率会越小,进而导致权重衰减也越小,这在一定程度上抵消了 weight decay 的作用. 按照weight decay原始的概念, 把它加到了优化器作用之后, 使其与learning rate完全脱钩, 真正发挥weight decay的作用:
AdamW(Adam Weight Decay Regularization) 便是 weight decay 形式的 Adam. 由于 Adam 中自适应的学习率通常比较小,因此需要较大的 weight decay 系数。 AdamW类似L2能达到同样使参数接近于 0 的目的。那么,AdamW 权重衰减总是比 Adam 的 L2 正则化更好? 不一定, 但通常不会更差。
Caffe 上的实现参考这里。
在分布式训练场景中, 每个计算设备上的batch size固定时,设备数越多,全局的batch size越大。但过大的 batch size 会带来训练的收敛问题:refer1 ,refer2
- 模型最终精度损失
- 收敛速度变慢, 需要更多的epoch 才能收敛
LARS 和 LAMB 两个优化策略常用来解决上述超大batch 训练中的收敛问题。
LARS通过应用逐层自适应学习率(layerwise adaptive)使得用 ImageNet 训练RESNET只需要几分钟。
以SGD为例阐述逐层自适应学习率的思想:
对梯度(更新量)进行normalization(l2-norm),再进行缩放,可看作对学习率的缩放。缩放因子采用关于权重的函数:\(\phi\left(\left\|x_t\right\|\right)\)
特别的是,l2-norm是针对多层神经网络的每一层分别进行norm。
出发点:有时候 \(g_t\) 的模长会大于参数 \(x_t\) 的模长,这可能会导致更新的不稳定。所以,一个直接的想法是:每一层的参数的更新幅度应该由 \(x_t\) 的模长来调控。
归一化的优劣:归一化会丢失梯度的大小仅保留方向,这导致梯度的更新biased,但在较大的batch学习的情况下问题会被弱化。但能带来明显的好处:对梯度爆炸、梯度消失的现象更鲁棒。
其中,\(x_{t}^{(i)}\) 表示第t步第i层的权重。\(\phi\) 是一个可选择的映射函数,保证norm之后的梯度与权重有相同的数量级。论文给出的两种映射函数为:(1)\(\phi(z)=z\);(2)起到min-max归一化作用的\(\min(\max(z,\gamma_l),\gamma_u)\)。\((\gamma_l,\gamma_u)\)为预先设定的超参数,分别代表参数调整的下界和上界。
LARS、LAMB算法的伪代码如下:

其中\(m_t=β_1m_{t?1} + (1 ? β_1)(g_t + λx_t)\) 这个一阶动量计算方式类似带 的 优化器,LARS在其基础上进行norm与缩放。LARS公式还可以写成如下形式,在带 的 优化器的基础上加入了 的逻辑, 对每一层的 进行放缩。
LAMB 出自 Large Batch Optimization for Deep Learning: Training BERT in 76 minutes(ICLR 2020)
该方法由Google brain团队于2019年提出,用于加速BERT预训练,在不降低精度的前提下增加了batch size,通过充分利用GPU、TPU等计算资源使得整体耗时较低(并非减少了模型权重或优化器的参数量)。
实验发现LARS在不同模型上表现不稳定,比如BERT这类Attention模型表现不佳。作者从公式理论的角度对此做了分析(附录包含一堆公式)。
LAMB(Layer-wise Adaptive Moments optimizer for Batching training)优化器基于Adam对LARS进行了改进,旨在解决超大batch的训练收敛问题。在不降低精度的前提下增大训练的批量大小,其支持(adaptive element-wise updating)和(layer-wise correction)。
LAMB算法参数更新如下:
相比于LARS, LAMB 仅替换了内层优化器为包含二阶动量和偏差校正的Adam优化器,也是在内层优化器的基础上, 套了一个 的逻辑, 对每一层的 进行了放缩。
这一简单的调整所带来的实际效果非常显著。使用 AdamW 时,batch size 超过 512 便会导致模型效果大幅下降,但在 LAMB 下,batch size 可以直接提到 32k 而不会导致精度损失。LAMB也可作为通用优化器,训练小批量的样本。
参考:
不成熟的观点:Adam等自适应学习率算法对于稀疏数据具有优势,且收敛速度很快;但精调参数的SGD(+ Momentum)往往能够取得更好的最终结果。
论文 Improving Generalization Performance by Switching from Adam to SGD 给出了一种先使用 Adam 训练,再在合适的时机转成 SGD 的组合方法.
大部分 NLP 预训练模型已不再使用SGD、AdaGrad、RMSprop这些方法,而是使用后来提出的 AdamW 和 LAMB 等。
可以预见到未来一定还会出现更多更好的优化算法。
以线性回归为例:
hyposis: \(h_ heta(x)=\sum_{j=0}^n heta_jx_j\)
m是样本的总数,n是参数\( heta\)的总数.
优点: 全局最优解, 便于并行实现
缺点: 训练速度慢, 难以动态新增样本
总体 cost: \({ ext{cost}}( heta)={1\over 2m}\sum_{i=1}^m(h_ heta(x^{(i)})-y^{(i)})^2\)
一次梯度下降所做的操作如下,重复迭代多次:
单个元素的loss: \(J( heta,(x^{(i)},y^{(i)}))={1\over 2}(h_ heta(x^{(i)})-y^{(i)})^2\)
- 对训练样本随机打乱顺序
- 重复如下的梯度下降:
for i=1,...,m{
? \( heta_j:= heta_j-\alpha{\partial\over\partial heta_j}J( heta,(x^{(i)},y^{(i)})) ag{for j=1,...,n}\)
}
由于一次只使用一个样本,因此多了一层循环.但是实践中很少使用,因为优化的向量运算比单个处理快。有时人们把SGD指代Mini-batch Gradient Descent(因为通常mini-batch的选择是随机的)。
与Batch gradient descent相比,其收敛的曲线可能比较振荡.
优点: 训练速度快, 可以新增样本
缺点: 并非全局最优解, 不便于并行实现
每次计算梯度只使用训练集的一小部分,常见的mini-batch大小是32/64/128(优化的向量).例如,ILSVRC ConvNet使用256个样例.
设b是mini-batch的样本数,融合Batch gradient descent与Stochastc gradient descent的思想,重复如下的梯度下降:
for i=1,1+b,1+2b,...,~m{
? \( heta_j:= heta_j-\alpha{1\over b}\sum_{k=i}^{i+b}{\partial\over\partial heta_j} ext{cost}( heta,(x^{(k)},y^{(k)})) ag{for j=1,...,n}\)
}
通过向量化的计算方式,其可能比Stochastc gradient descent计算速度更快.
优点: 可以降低参数更新时的方差
缺点: 受学习率影响大
前面讨论的方法都是一阶方法(first order),更有效的方法是基于牛顿法:
牛顿法利用了函数的一阶和二阶导数信息,直接寻找梯度为0的点。牛顿法不能保证每次迭代时函数值下降,也不能保证收敛到极小值点。在实现时,也需要设置学习率,原因和梯度下降法相同,是为了能够忽略泰勒展开中的高阶项。学习率的设置通常采用直线搜索(line search)技术。
牛顿法收敛速度更快,并且不需要超参数.然而计算Hessian矩阵的逆在时间和空间复杂度都非常高,不切实际.因此出现了许多变种方法(quasi-Newton methods)来计算近似的逆矩阵值.如方法 L-BFGS,(缺点是必须在整个训练集上计算,如何让其在mini-batches上工作是当前比较活跃的研究领域)
牛顿法原理: 牛顿法是对目标函数在当前点进行二阶泰勒展开, 然后求导求极值得到下一步更新的步伐.
将 \(f(x)\) 在 \(x_n\) 处二阶 taylor 展开, 有:
我们的目的是选择合适的 \(\Delta x\) 最小化目标函数 \(f(x_n+\Delta x)\) . 求导令导数为0得到:
其中的二阶项 \(f''(x_n)\) 就是 Hessian 矩阵.
针对牛顿法的缺点,目前已经有一些改进算法。这类改进算法统称拟牛顿算法。比较有代表性的是 BFGS 和 L-BFGS。
BFGS 算法使用低秩分解近似的方法来代替计算 Hessian 矩阵的逆,有效地提高了运算速度。但是我们仍然需要保存每次迭代计算近似逆矩阵所需要的变量的历史值,空间成本较大。
L-BFGS 是 limited BFGS 的缩写,是对BFGS 算法的改进,简单地只使用最近的m个历史值. 算法不需要存储 Hessian 近似逆矩阵, 而是直接通过迭代算法获取本轮的搜索方向,空间成本大大降低。
牛顿法通常快于梯度下降法,可以看作是梯度下降法的极限(Hessian矩阵的逆可以看作梯度下降法的学习率的部分)。牛顿法的步长是通过导数计算而来的。所以当临近鞍点的时候,步长会变得越来越小,这样牛顿法就很容易陷入鞍点之中。而sgd的步长是预设的固定值,相对容易跨过一些鞍点。
总的来说,基于梯度下降的优化算法,在实际应用中更加广泛一些,例如 RMSprop、Adam等。但是,牛顿法的改进算法,例如 BFGS、L-BFGS 也有其各自的特点,也有很强的实用性。
牛顿法的改进参考:
- Large Scale Distributed Deep Networks is a paper from the Google Brain team, comparing L-BFGS and SGD variants in large-scale distributed optimization.
- SFO algorithm strives to combine the advantages of SGD with advantages of L-BFGS.
- https://www.zybuluo.com/evilking/note/973214
- https://blog.csdn.net/itplus/article/details/21897715
- http://www.hankcs.com/ml/l-bfgs.html
解决的是SGD可能遇到鞍点的问题,利用了二阶梯度信息.
\(H_d\)是L(x)的Hessian矩阵的对角线元素,且x服从正向分布(\(x\in \mathcal N(0,1)\)).
一种推荐的激活函数选择是增加一个较小的线性项,使其减少饱和区域,如:\(f(x)= anh(x)+ax\).
在参数更新时可以引入梯度噪声\(g_i=g_i + \mathcal N ( 0,\sigma )\).
- Hogwild
- Downpour
包含两个关键部分:模型复制和参数服务器。
在内存受限的条件下增加batch size的技巧:连续的多个batch的梯度累加后进行一次反向传播。
一方面能够减少反向传播的计算次数,另一方面适当地增加batch size,累计梯度也能更稳定一些(平滑极值)。
- Stanford University CS231n 公开课
- 李沐等著《动手学深度学习》d2l.ai
- Adam那么棒,为什么还对SGD念念不忘 (1) —— 一个框架看懂优化算法
- Adam那么棒,为什么还对SGD念念不忘 (2)—— Adam的两宗罪
- Adam那么棒,为什么还对SGD念念不忘 (3)—— 优化算法的选择与使用策略
- Adam,AdamW,LAMB优化器原理与代码
 上一篇
上一篇 



