

本篇博客为论文 Learning to Optimize[^1]的总结。
在上一篇文章中我们谈到了GPS算法并介绍了三个不同的版本,在这里我将介绍GPS-V3在数值优化领域的应用——利用强化学习算法自动设计(无约束连续)优化算法。具体来说,任意优化问题可以抽象为如下过程:

不同的优化算法只是在的选取上有所不同。例如,梯度下降方法为以下形式:
带动量的梯度下降为以下形式:
那么采用强化学习方法时,只要将策略函数设置为上述策略即可。但是
的形式太多了,搜索空间过大会使得算法训练起来难度较大。因此在这里我们限定
的输入只包括当前数据点与之前访问过的数据点对应的函数值以及梯度值,也就是说搜索空间包含了所有的一阶优化方法。
下面将分别介绍将以上过程建模为MDP后的状态空间、动作空间、环境模型以及回报函数:
- 状态空间。 一共包含如下三个方面:1)当前数据点;2)当前数据点对应的函数值与之前H个数据点对应的函数值的差值;3)之前H个数据点对应的梯度值。
- 动作空间。 即算法1中的
,当然数据点一般是多维的,因而论文中将每一维都设定为从一个高斯分布中进行采样。其中均值就是策略网络的输出,方差是某个预先设定的默认值。这里值得注意的是,策略网络的输入是不包括之前说明的状态空间中的第一项——也就是当前数据点——因为优化算法不应该根据当前的绝对的数据点来去确定算法优化方向以及步长的。
- 环境模型。 这里的环境模型是未知的,需要进行估计,所以我们需要采用GPS-V3算法。
- 回报函数。 由于评价一个优化算法的好坏主要关注其收敛速度的快慢,因而论文中将回报函数设置为当前数据点对应的函数值,这样就可以鼓励学习到的策略尽可能快的去达到目标函数的局部最优解处(这里我其实有些不理解,我觉得仅仅将函数值设置为回报函数是不够的,还需要每一步都给一个小于0的回报,这样才能学习到一个尽可能快地到达局部最优解的策略,但是后面的实验表明这样就足够了)。
接下来要讲的就是如何去训练我们的GPS-V3算法了。GPS-V3算法的训练都需要一个仿真环境,在这里其实就是具体的目标函数。比如我们要自动学习出一个解逻辑回归对应的优化问题的优化算法,那么仿真环境或者训练数据其实就是不同的数据集下的逻辑回归损失函数,这里的数据集都是从高斯分布中随机采样的。训练完成之后,就可以将优化算法应用到实际数据集对应的逻辑回归损失函数上了(这里应用到实际数据其实包含两种实际数据,第一种是与训练数据不同但是分布相同的测试数据,一种是分布也不同的测试数据,显然后者更加符合实际情况。论文对这两种数据都进行了实验,并且后一种数据的实验结果也很好,说明算法的迁移学习能力较强)。
从上面的描述可以看出,自动学习优化算法的局限性在于对于一种新的形式的优化问题就需要重新训练。至于不同优化问题之间的迁移性如何论文没有给出具体的实验。为了加速算法训练,在GPS-V3算法初始化时,初始策略不是随机策略,而是用带动量的梯度下降进行初始化(就是监督学习)。
下面将展示在三种不同的损失函数上GPS-V3算法学习到的优化算法相比于一些经典的优化算法(梯度下降、带动量的梯度下降、共轭梯度法以及L-BFGS算法):
逻辑回归
逻辑回归问题对应的损失函数如下:
这是一个凸优化问题,最终在测试集上的性能如下图所示:
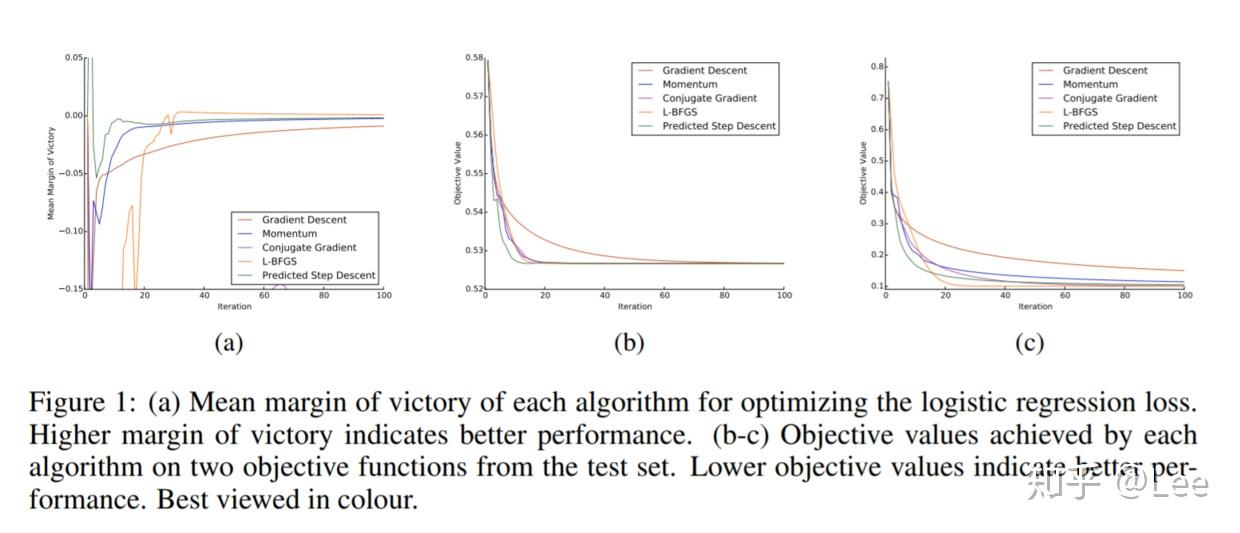
可以看出自动学习到的算法除了L-BFGS比不过之外,其余都是没问题的。而L-BFGS之所以比不过是因为其在解决凸优化问题上是一个非常非常好的算法。这里值得注意的是第一张图所用的评价指标,它代表在每一次算法迭代时,当前算法对应的函数值与所有算法效果最好的算法对应的函数值之间的差值,因而有正有负,越大越好。
鲁棒线性回归
鲁棒线性回归算法对应的损失函数如下:
这是一个非凸优化问题,算法性能对比如下:
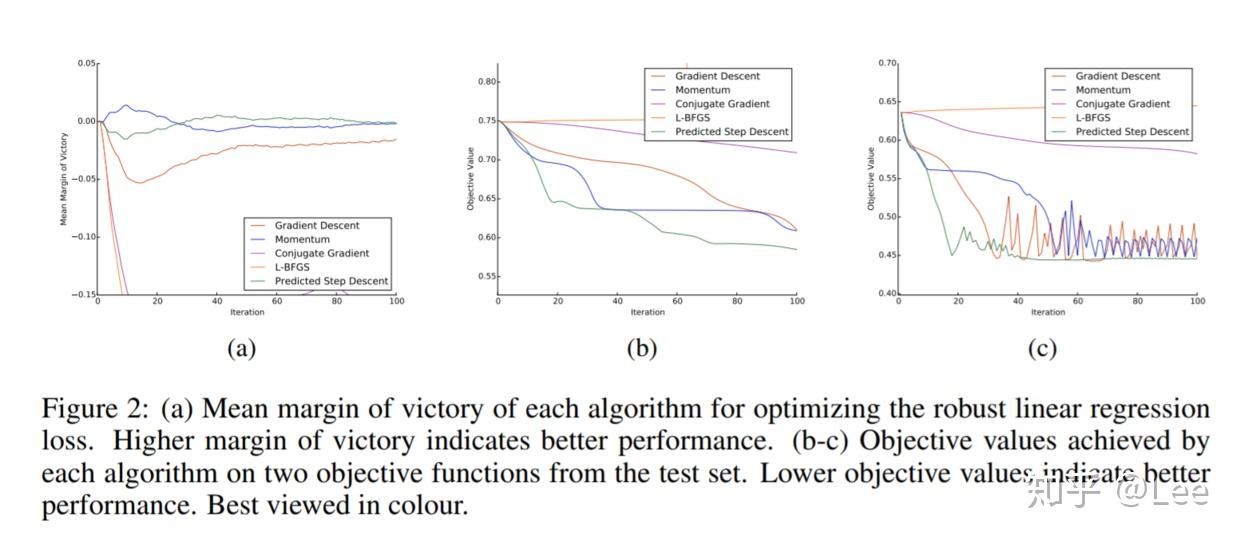
可以看出,对于非凸优化问题,基准算法容易出现发散、震荡、收敛到局部最优解的现象,这些自动学习出来的优化算法都没有出现。
两层神经网络
一个带有ReLU隐含层非线性激活函数以及softmax输出层非线性激活函数的两层神经网络对应的损失函数如下:
这是一个局部最优解更多的非凸函数,算法性能对比如下:
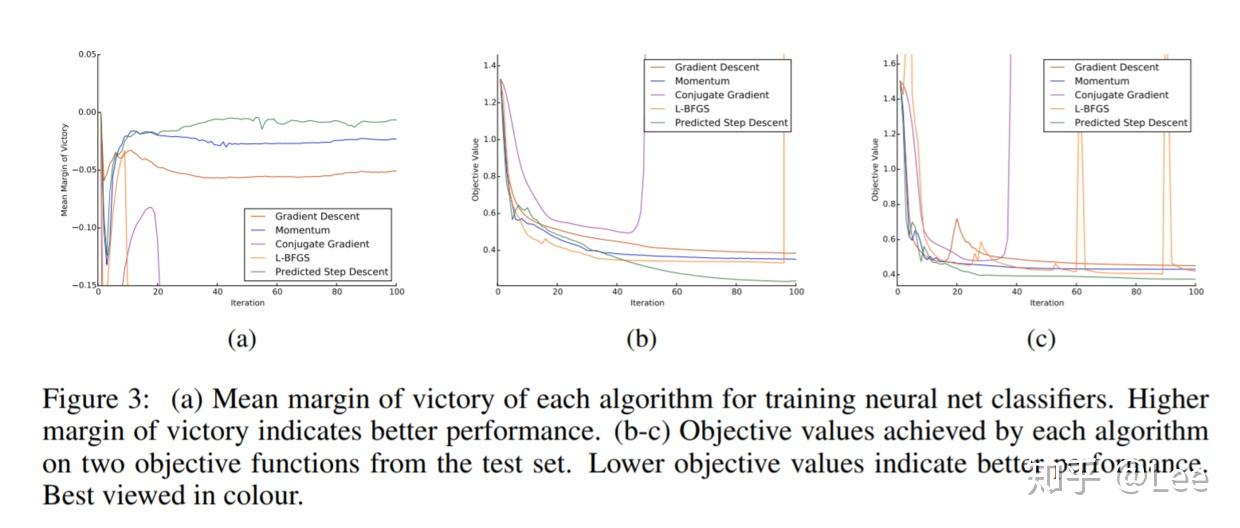
可以看出,自动学习到的优化算法的优势更加明显。
下面来让我们从优化算法在损失函数曲面上的优化路径来看看不同算法的区别:
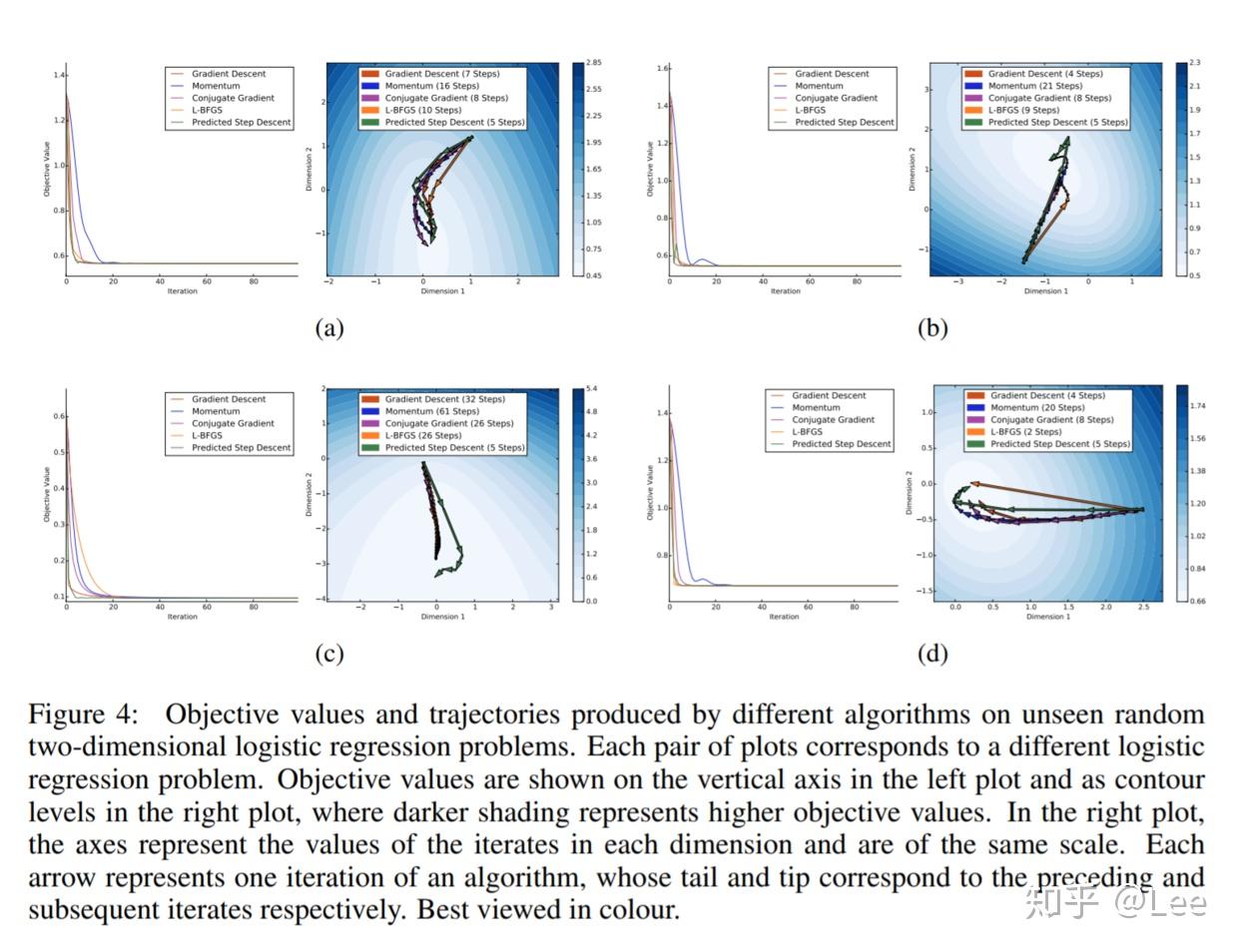
可以看到,自动学习出的优化算法通过训练样本对损失函数曲面结构有了充分的认知,使得其可以采用非常大的步长。
最后,看看算法在不同分布的测试数据上的性能,其中混合高斯分布中混合的分布越多,代表测试数据的分布与训练数据差异越大:
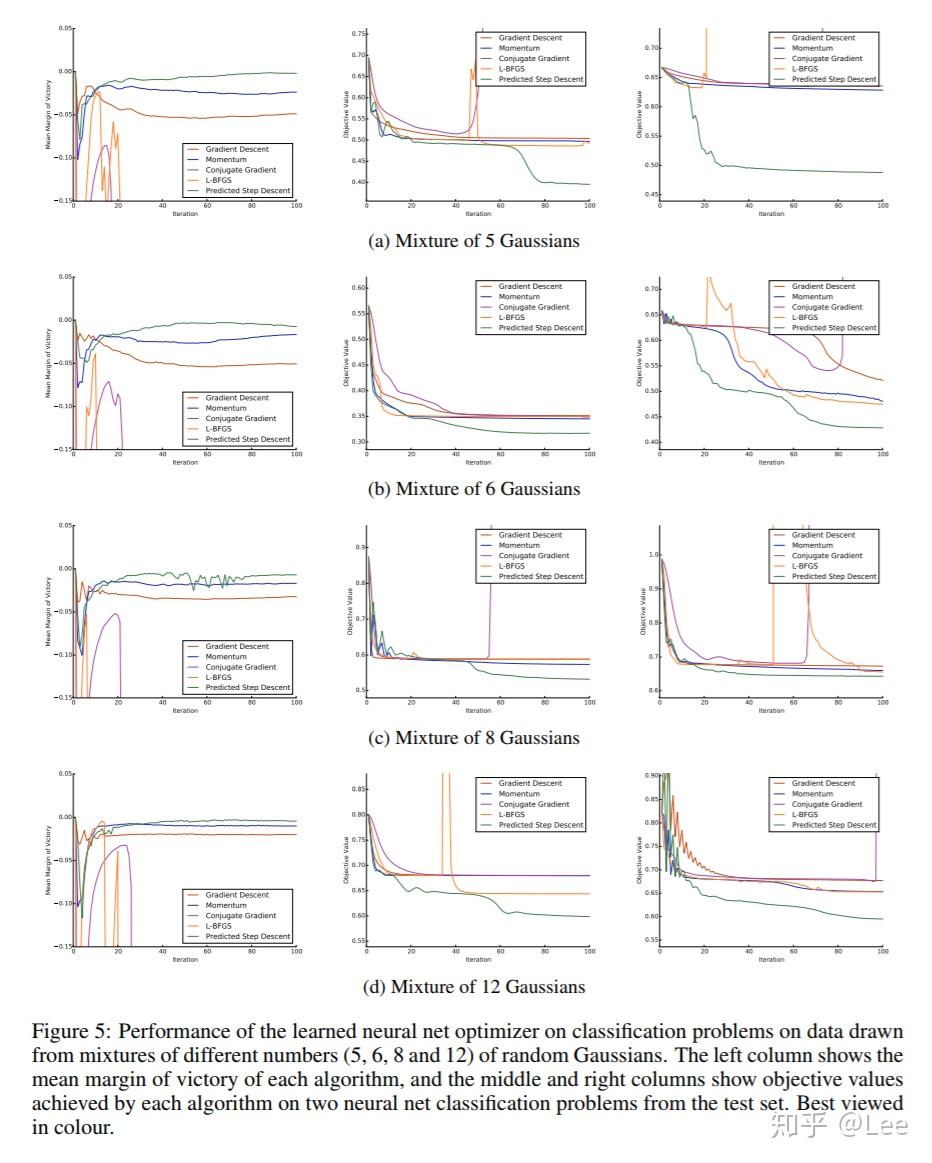
可以看出,自动学习到的优化算法在不同数据分布上更为稳定,而且算法性能也更好。
[^1]: Li, Ke, and Jitendra Malik. "Learning to optimize." ICLR (2017).
 上一篇
上一篇 




