

1、背景
AI换脸 (face-swap)是指用另一个人脸来替换一张图片或视频中的一个人脸,合成新的媒体物,它是Deepfake(“深度伪造”)技术最广为人知的一种应用形式。Deepfake是指基于深度学习等机器学习方法创建或合成视听觉内容,如图像、音视频、文本等。
Deepfake的制作和检测研究自2017年以来,相关论文数从3篇增加到150篇以上(2018-19年)。本报告以Deepfake技术为主线索,重点阐述AI换脸技术的发展、原理及其应用。

图1-1 deepfake换脸示例(左边是原人脸图像,右边是替换人脸后图像)
Deepfake技术发展过程(截止2020.01,涵盖AI换脸):
2014.06:提出生成对抗网络(GAN),在图片创建方面取得重大突破,之前的AI算法可以较好的分类图片但创建图片困难;
2017.07:提出一种使用RNN 的LSTM(Long Short-Term Memory)学习口腔形状和声音之间关联性的方法,仅通过音频即可合成对应的口部特征;
2017.10:提出一种基于 GAN 的自动化实时换脸技术;
2017.12:出现deepfake色情视频,名人的面孔被换成色情演员的面孔,由Reddit用户使用自动编码器-解码器配对结构开发(FakeApp前身);
2018.04:出现美国前总统奥巴马的deepfake演讲,将声优的口型(含模仿的配音)替换到奥巴马演讲视频中,使用了FakeApp;
2018.08:提出一种将源视频中的运动转移到另一个视频中目标人的方法,而不仅是换脸(效果imperfect);
2019.03:提出一种控制图片生成器并能编辑造假图片各方面特性的方法,比如肤色、头发颜色和背景内容,不同于之前的假人图片生成方法,这是一种重大突破;
2019.05:提出一种真实头部说话神经模型的少样本对抗学习,基于GAN元学习,该模型基于少量图像(few-shot)训练后,向其输入一张人物头像,可以生成人物头像开口说话的动图;
2019.06:出现“一键式”智能脱衣软件 Deepnude,迫于舆论压力,开发者快速下架。
2020:主要进展在提高原生分辨率、提升deepfake制作效果方面。
从视觉角度,deepfake一般可划分四类:重现(reenactment)、替换(replacement)、编辑(editing)、合成(synthesis)。
尽管人脸编辑和合成研究火热,但重现和替换才是最大的隐患,它们可以让攻击者控制身份和欺骗。
重现使用源身份Xs驱动目标身份Xt,使得Xt的行为和Xs一样,包括表情、嘴部、眼部、头部及躯干。
l 表情重现
让Xt模仿Xs的表情,可用于电影行业中后期调整演员的表情表演、教育行业中对历史人物表情再现讲解事物。
l 嘴部重现
也称“配音”,Xt的嘴部由Xs驱动,或者是包含语音的音频输入,可用于将逼真的语音配音成另一种语言并进行编辑。
l 眼部重现
Xs视线驱动Xt眼睛的方向和眼睑的位置,可用于改善照片质量或在视频采访中自动保持眼神交流。
l 头部重现
Xt头部位置由Xs驱动,可用于在安全录像中对人脸进行朝向转正,并用作改善人脸识别软件的手段。
l 身体重现
也称姿态迁移和人体姿势合成,与面部重现类似,是身体躯干的重现。
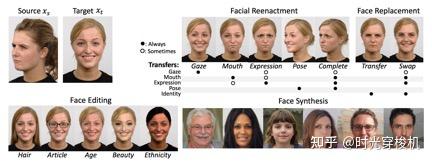
图2-1 人脸重现、替换、编辑、合成分别生成的deepfake示例
攻击模型:攻击者能用其假冒身份,假冒他人说或做,比如诽谤、散布错误信息、篡改证据、骗取信任诈骗、生成虚假材料勒索等。
替换使用源身份Xs的内容替换目标身份 Xt,使得目标身份变成了源身份Xs。
l 转移(transfer)
使用Xs的内容替换 Xt,常见是面部转移(即用Xs的脸直接覆盖 Xt的面部),在时尚行业中用于不同服装中的个人虚拟试穿。
l 交换(swap)
由Xt驱动Xs的内容转移到 Xt(从效果上看,Xt原有的面部表情等会被保留),最流行的是“换脸”,比如将某人的身份同名人的身份交换来产生讽刺或不良的内容效果、一种健康用途是在公共场合或平台匿名化身份以代替模糊或像素化。

图2-2 人脸替换生成的deepfake示例
攻击模型:替换技术因其有害应用而闻名,比如攻击者将受害者的脸换到色情女演员的身体上,以侮辱、诽谤和勒索受害者,还可将一个人的脸转移到一个看起来相似的身体上充分再现此人。
编辑是指添加、更改或删除目标身份的属性,比如,更换目标对象的发型、衣服、胡须、年龄、体重、颜值、眼镜和种族等属性。

图2-3 编辑属性生成的deepfake示例
攻击模型:攻击者可以使用相同的过程来建立虚假的角色误导他人,比如,可以使一个患病的领导者看起来健康的,震慑“敌方”,一个不道德的用途是去除受害者的着装使其裸露,即所谓的一键脱衣。
合成是指在没有目标身份作为基础的情况下创建deepfake角色,类似直接用GAN或者其它生成模型生成人脸,没有明确的target。人脸和身体合成技术可以创建影视素材,生成电影和游戏角色。

图2-4 全脸合成生成的deepfake示例
攻击模型:攻击者可以在线创建虚假角色进行诈骗等违法活动。
通常使用5种神经网络的变种或组合构建深度伪造生成网络:编码-解码网络(Encoder-Decoder, ED)、卷积神经网络(Convolutional neural network, CNN)、生成对抗网络(Generative adversarial networks, GAN)、图像转换网络(Pix2Pix, CycleGAN)、递归神经网络(Recurrent neural network, RNN)。
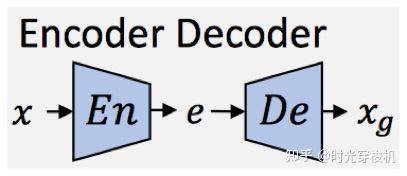
图3-1 编码-解码网络架构
网络至少包含一个编码器En和一个解码器De,连接编码和解码的中间层较窄,因此当训练De(En(x))=xg时,网络将被迫学习、汇总训练样本的高层语义概念。
给定x的分布X,En(x)=e,通常称e为编码或嵌入(embedding),而E=En(X) 被称为“潜在空间(latent space)”。
Deepfake技术通常使用多个编码器或解码器,并操纵编码来影响输出 xg。如果编码器和解码器是对称的,并且以目标 De(En(x))=x训练网络,则该网络称为自动编码器(Autoencoders),输出是x的重建。
ED的另一种特殊类型是变分自动编码器(VAE),其中编码器学习给定X的解码器后验分布。VAE比自动编码器在生成内容方面更好,因为潜在空间中的表征可以被更好地解耦。
自动编码器提取面部图像的潜在特征,使用解码器重建面部图像,为了在源图像和目标图像之间交换面部,需要两个编码器/解码器对。
两对具有相同构造的编码器网络,各自在图像集上训练,编码器的参数在两个网络对之间共享。(有点encoder“求同”、decoder“存异”的味道)
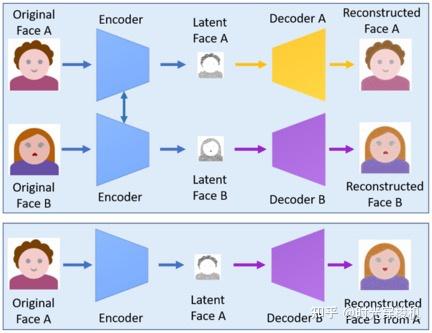
图3-2 使用两个编码器/解码器对的Deepfake创建模型
该策略使通用编码器能够找到并学习两组面部图像之间的相似性,面部通常具有相似的特征(例如,眼睛,鼻子,嘴巴的位置),这是较为不具挑战性的。
两个网络使用相同的编码器编码,但使用不同的解码器训练解码过程(图3-2上部),人脸A的图像使用通用编码器编码,并使用解码器B解码,以创建一个deepfake(图3-2下部),人脸的角度、表情以及头型的相似度影响人脸替换的效果。

图3-3 基本的CNN网络架构
与全连接网络相反,CNN擅长学习数据中(局部)结构模式并组合得到高层次表征,因此在处理图像方面效率更高。
CNN中的卷积层学习的是卷积核/滤波器参数,这些滤波器在输入图像上移动,提取抽象的特征图作为输出。
随着网络变得越来越深,池化层降低维数,上采样层提高维数;它们可以灵活地构建用于图像的ED CNN。
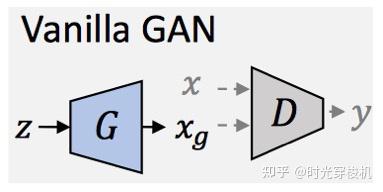
图3-4 Vanilla GAN网络架构
GAN由Goodfellow等人于2014年首次提出,源于博弈论“零和博弈”思想,通过生成模型G (generative model) 和判别模型D (discriminative model) 互相博弈的方法来学习数据分布的生成式网络。
G旨在欺骗D来创建伪样本,它通过给定某种隐含信息,随机生成观测数据样本;D学会区分真实样本(x∈X)和伪样本( xg=G(z) 其中z ~ N),它预测数据样本是否属于真实训练样本。
具体来说,有一个分别用于训练D和G的对抗损失:
Ladv (D)=maxlogD(x) + log(1?D(G(z)))
Ladv (G)=minlog(1?D(G(z)))
在对抗博弈下,两者通过对抗式训练提升其能力,G学习如何生成与原始分布无法区分的样本。训练后,将D丢弃,并使用G生成内容。
最理想的状态是生成模型能够生成足以“以假乱真”的数据样本, 而判别模型却对其真伪性难以判别,即判断正确的概率只有 50%。
GAN优势是不依赖先验知识,生成模型的参数更新来自判别模型的反向传播,而非直接来自于数据样本,故训练不需要复杂的马尔科夫链。当应用于图像时,通常可以生成更高质量、逼真的图像样本。
Pix2Pix和CycleGAN是两种流行的使用GAN基本原理的图像转换网络。
(1)Pix2Pix可以完成从一个图像域到另一个图像域的转换。
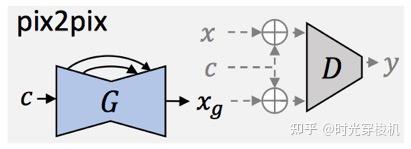
图3-5 Pix2Pix网络架构
在Pix2Pix中,G以输入图像x c作为输入,在给定目标标签x,希望G学习xc -> x的映射,即希望G所生成的图像xg和x无限接近,而D区分 (x, xc) 和 (xg, xc)。
Pix2Pix是一种监督式、成对式的训练方式,对数据有严苛要求,提升版本的Pix2PixHD可用来生成具有更好保真度的高分辨率图像。
(2)CycleGAN可以通过不成对的训练样本来进行图像转换。
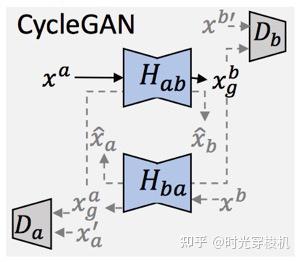
图3-6 CycleGAN网络架构
该网络由两组GAN构成,并形成一个循环约束:将图像从一个域转换为另一个域,然后再次返回时,确保一致性。

图3-7 RNN网络架构
RNN可以处理序列和可变长度数据的神经网络,RNN的更高级版本包括长期短期记忆(LSTM)和门递归单元(GRU)。
在Deepfake制作中,RNN通常用于处理音频、视频。
大多数神经网络结构使用一些中间表示来捕获、控制源身份s和目标身份t的面部结构、姿势和表情等,常见的各种方法如下。
l 使用面部动作编码系统( facial action coding system,FACS)并测量面部的每个分类动作单元(AU)。
l 使用单目重建,从2D图像获得头部的3D可变形模型(3DMM),其中,姿势和表情使用矢量和矩阵参数化、头部使用参数或3D渲染。
l 使用头部或身体的UV图来使网络更好地了解形状的方向。
l 使用图像分割来帮助网络分离不同的语义区域(面部、头发等)。
l 最常见的表示形式是特征点(也称为关键点),即面部或身体上一组定义的位置点(利用开源CV库可有效跟踪)。
l 有的按通道分隔特征点,以使网络更容易标识和关联它们。
l 类似地,面部边界和身体骨骼点的表示等。
l 对于音频,常见方法是分割音频段,衡量音频段的Mel-Cepstral Coefficients(MCC)捕获主要语音频率。
一个deepfake网络一般被设计或训练只针对特定的目标身份和源身份生效。身份不可知模型有时很难实现, 这是因为模型在训练期间学习了s和t的相关性。
定义E:表征x的特征或从x提取特征的模型或过程;M:一个训练后的模型,用于实现重现或替换;据此定义模型的3种泛化类别。
l one-to-one
用特定身份驱动特定身份:xg=Mt (Es (xs))。
l many-to-one
用任意身份驱动特定身份:xg=Mt (E (xs))。
l many-to-many
用任意身份驱动任意身份:xg=M (E1(xs), E2 (xt))。
l 泛化性
生成网络是数据驱动的,因此在所生成的结果中反映了训练数据的特性;良好的效果受限于训练数据集,特定身份的高质量图像需要该身份的大量样本;获取驱动对象的训练数据通常比受害者的容易的多;如何最小化训练数据,并使训练过的模型在新的目标身份和源身份(非训练数据)上也生效。
l 成对式监督训练
带标签成对具有GT(ground truth,正确打标记的数据)的数据实在难以获取。对此,许多deepfake网络通过使用自监督的方式进行训练,或者使用不成对的网络(例如CycleGAN),或者利用ED网络的编码在潜在空间进行特征编辑。
l 非期望特征迁移
有时会把源身份的特征或区域迁移到目标身份上,对此提出使用注意力机制、few-shot学习,解耦学习、跳跃连接等方法将更相关的信息传递给生成器。
l 遮挡
遮挡可能是手、头发、眼镜或任何其它物品,还有眼睛或嘴巴被隐藏或动态变化,这可能导致(裁剪的图像、不一致的面部特征)出现伪影、不合理的生成效果等,对此提出对障碍物进行分割和修补。
l 时间连贯性
Deepfake视频通常会产生更明显的伪影,例如闪烁和抖动,是因为大多数deepfake网络无先前帧的上下文、单独处理每个帧,对此提出将上下文提供给G和D,或进行时间连贯损失约束,或使用RNN,或对它们进行组合使用。
每个制作方法有不同的成本和收益,最有效和最具威胁性的方法是:(1)最具实施性(训练数据、执行速度、可访问性);(2)对受害者最可信(质量/可信度)。
l 数据&质量
用大量数据训练的模型产出的效果通常更好,但需许多小时的训练素材,仅适用于知名人士。
对任意个人的攻击需使用具有many-to-many泛化能力的模型或少样本学习方法,这类模型必须“想象”缺少的信息(例如姿势、遮挡),通过提供数量有限的参考样本可达成数据和质量之间的折衷。
l 速度&质量
这两者之间的取舍取决于攻击是在线(交互式)或离线(存储媒体),此类社会工程学攻击通常是在线的,需要实时速度。
但高分辨率的模型具有许多参数、可能会使用多个网络、可能会处理多个帧以提供时间连贯性;其它方法可能会因预处理/后处理步骤变慢。
已知的声称能实时产生伪造品的模型在主观上趋于模糊或扭曲面部。当在遭受社会工程学攻击的虚假误导压力之下,不完美的伪造品很可能对受害者是有效的。
攻击者很可能在低分辨率水平上实施复杂的方法以加快帧速率。对于非实时攻击,分辨率和保真度重要,具有时间连贯性的高质量图像和视频是最佳选择。
l 可访问性&质量
可访问性和可复现性是新技术扩散的关键因素,在网络公开发布的代码和数据更有可能被研究人员和罪犯使用,这是因为相比使用网络上有效可用的方法,复现论文的收益很小。
考虑以上因素,以下是目前最重要和最可用的深度伪造技术:
(1)面部重现:高效和实用性;
(2)嘴巴重现:质量高;
(3)人脸替换:高保真度和广泛传播使用。
除了质量,当前的深度伪造制作还存在一些局限性技术。
l 重现总是以正面姿势驱动和生成
这导致重现的表现非常静态,可通过换脸把身份交换到相似的身体上避免,但不一定总能做到很好的匹配,实用性有限。
l 重现和替换依赖驱动器的表现来交付身份的特性
下一代的深度伪造将利用目标的视频生成具有期望的表情和举止的内容,使得创建令人信服的深度伪造过程更加自动化。
l 连贯渲染
头发、牙齿、舌头、阴影的连贯渲染,以及渲染目标目标手的能力(尤其是在触摸脸部时)。
l 原生分辨率

图3-8 深度伪造支持的原生分辨率进展
用于训练的数据原生分辨率每增长P,则训练时长至少增加P^2。
总体分为三个核心步骤:数据收集、模型训练、伪造内容生成。
l 数据收集
大量源和目标人物的人脸照片,尽可能覆盖人脸的各种角度。
l 模型训练
训练耗时依赖硬件配置、训练数据的质量。
l 伪造内容生成
对于生成目标xg,重现和人脸替换类型的网络一般遵循以下流程(将x传递到以下pipeline):
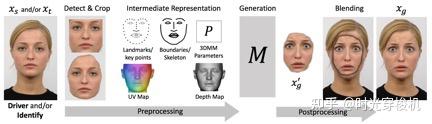
图3-9 重现和人脸替换处理pipeline(通常仅执行部分步骤)
(1)检测并裁剪面部;
(2)提取中间特征表示;
(3)根据一些驱动信息(如另一张脸)生成新的面部内容;
(4)将生成的脸融合到目标帧中。
l 通常使用的6种驱动图像生成的方法
(1)让网络直接在图像上执行映射学习;
(2)使用ED解耦身份和表情并在传递给解码器前修改/交换编码特征;
(3)在将其传递给解码器之前添加其它编码(如AU、embedding);
(4)在生成之前将中间人脸/身体的特征表示转换为所需的身份/表情;
(5)通过源视频帧序列的光流场驱动生成;
(6)使用3D渲染、扭曲的图像或生成的内容进行组合,以创建原始内容(头发、场景等)的合成,然后将该合成(粗略结果)传递给另一个网络( 例如pix2pix)以改善真实感。
Reddit社区原始的deepfake使用ED网络:1个编码器En,2个解码器Des和Det,作为2个autoencoders同时训练:Des (En(xs))=Xs,Det (En(xt))=Xt,其中x是裁剪出的人脸图像。En学会将s和t映射到共享的潜在空间:Des(En(xt))=xg。
基于Reddit原始网络的更强大开源换脸工具有FaceSwap(34K星)、DeepFaceLab(23K星,95+% deepfakes的制作工具)、FaceSwap-GAN(3K星)等,支持了更多的模型,这些模型泛化能力均是one-to-one。

图3-10 Reddit社区“deepfakes”模型及变种
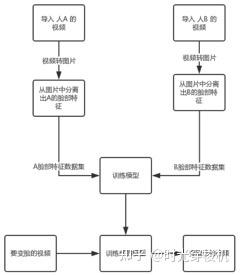
图3-11 整个换脸过程
(1)数据收集
收集大量目标人脸的原始照片,提取目标人脸;
(2)模型训练
对于64px input,64px output,训练原始模型GPU耗时约12-48小时,比如(CUDA + GPU + TensorFlow),CPU耗时约数周;
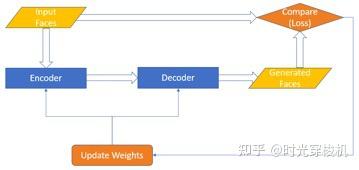
图3-12 基本的编码-解码网络训练过程
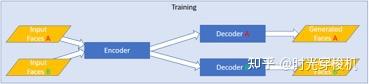
图3-13 自动编码解码网络训练过程
用2个数据集训练共享的Encoder和 2个Decoder,Decoder A试图重建Face A、Decoder B试图重建Face B;
(3)伪造内容生成:向训练过的模型输入人脸图像,用模型输出的人脸,混合生成伪造内容。
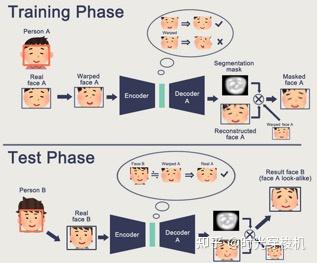
图3-14 人脸转换过程
可被用于误导舆论、扰乱社会秩序,甚至可能会威胁人脸识别系统、干预政府选举和颠覆国家政权等,已成为当前最先进的新型网络攻击形式。
(1)色情制作:2017年网络上显著出现,Deeptrace公司调研估计换脸视频96%是色情(2019.10);
(2)虚假新闻:发布或歪曲知名政客的言论,愚弄公众等;
(3)语音诈骗:利用合成的语音进行金融诈骗;
(4)影像篡改:将个人面孔交换到电影明星身体插入影视剪辑中、移除CT或MRI医疗影像中证据进行保险欺诈。
可用于推动娱乐与文化交流产业的新兴发展。
(1)电影制作:电影制作中创建虚拟角色、视频渲染、声音模拟;
(2)人物复活:“复活”历史人物或已逝的亲朋好友,实现“面对面”沟通,创造一种新型的交流方式。
l 中国
2021年1月1日施行的《民法典》,第1019条首次创新性地规定,禁止任何组织或个人利用信息技术手段伪造等方式侵害他人的肖像权,回应了技术发展背景下应对肖像权进行更为严密保护的需求。此处的“信息技术手段”可能包括通过软件修图、伪造图片、通过AI技术换脸、抠像或对他人肖像进行高精度伪造等方式。
l 美国
《2018 年恶意伪造禁令法案》中将“deep fake”定义为“以某种方式使合理的观察者错误地将其视为个人真实言语或行为的真实记录的方式创建或更改的视听记录”,其中“视听记 录”即指图像、视频和语音等数字内容。
l 欧盟
2019 年 4 月 8 日发 布《人工智能道德准则》,将隐私和数据管理作为可信赖人工智能需要满足的七个要素之一。
Deepfake的快速发展和应用,给个人隐私数据、社会稳定和国家安全等造成了潜在威胁,针对深度伪造内容的检测和防御现已成为世界各国政府、企业乃至个人所关注的热点问题之一。
检测深度伪造(和人相关)的方法通常分为两大类:伪影识别法和无定向法。
基本原理是通过搜索特定类型的伪影,人眼对伪影或许不易察觉,但机器学习和取证分析法容易检测,以下定义7种类型伪影。
l 融合(Blending (spatial))
生成的内容重新融合到图像帧时会产生一些伪影,检测方法比如边界检测、质量度量、频率分析。
l 环境(Environment (spatial))
伪造的脸部内容和图像帧的剩余部分可能是不协调的,比如面部变形过程中的残差、光照、保真度变化。
l 取证(Forensics (spatial))
分析模型在伪造品中留下的细微特征和样式,比如GAN会留下独特的指纹可能用于识别生成器、分析相机的独特传感器噪声(PRNU)识别粘贴的内容、寻找视频中帧序列的残差、寻找缺陷并预测和监测脸部特征点(如头部姿势往往不一致)。
l 行为(Behavior (temporal))
基于目标人物大量的数据,监测举止和其它行为异常,比如对已录制的目标人物素材库建模、在没有目标素材参考的情况下检测音视频片段中感知的情绪的差异。
l 生理(Physiology (temporal ))
基于生成的内容缺少生理信号的假设,比如监测心率识别伪造的面部、监测皮肤下血容量(脉搏)、监测不规则的眨眼模式,相反也有利用脉搏信号构建deepfake模型。
l 同步(Synchronization (temporal))
不一致也是一个揭示因子,比如把把语音和嘴巴附近的特征点相关联检测视频配音攻击、检测嘴型和语音因素的不一致(如在嘴巴完全闭合的(B,P,M)音素上deepfake往往会失败)。
l 连贯(Coherence (temporal))
实际的时间连贯性很难伪造产生,由此检测产生的伪影,比如使用RNN检测闪烁和抖动、使用LSTM只检测面部区域、使用成对的顺序帧训练分类器以及改进网络专注于监测帧的光流、(同一个作者)使用LSTM预测下一帧并监测重建误差。
不同于专注于一种特定的伪影,无定向法通过训练通用的分类器,让神经网络决定分析的特征。通常,研究者采用两种方法:分类器和异常检测。
l 分类(Classification)
对于压缩图像,深度神经网络表现的比传统的图像取证工具更好。各种研究者展示了标准的CNN架构如何有效的检测伪造视频,比如使用真假图片对训练利用CNN构建的孪生网络、使用HMN网络架构同时考虑面部和以前见过的面部内容(出于担忧CNN可能仅能检测训练过的攻击)、使用全家桶方式将7种深度伪造CNN的预测结果输入至元分类器。
使用分类器检测伪造也存在问题,因为通过对抗性机器学习可以逃避检测。
l 异常检测(Anomaly Detection)
同分类相反,异常检测模型使用正常数据进行训练,部署期间检测异常值,这些方法不假设攻击的形式,对于未知的攻击创建方法泛化性更好,比如在人脸识别网络中度量神经元激活(相对于使用原始像素可获得更强的信号,能够克服噪声和其它失真)、训练一类VAE网络用于重建真实图像并对新图像计算其和重建图像两者均值的MSE、利用ED隐空间度量输入图像和真实样本的embedding距离、不直接使用神经网络而使用最新的基于置信度指标(ABC)的属性(为了检测伪造图像,ABC用于确定图像是否适合预训练的人脸识别网络的训练分布)。
大多数图像检测方法不能用于视频,因为视频压缩后帧数据会严重退化。视频具有在帧组之间变化的时间特性,对于设计为仅检测静态图像的方法具有挑战性。
使用跨视频帧的时间模式的方法主要基于深度递归网络模型来检测deepfake视频,可分为两类:采用时间特征的方法和探索帧内视觉伪影的方法。
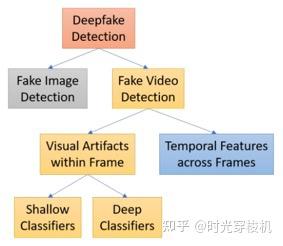
图5-1 深度伪造视频检测
利用视频流的时空特征来检测深度伪造,视频操作是在逐帧的基础上执行的,可以认为由面部操作产生的低级伪影会进一步表现为跨帧不一致的时间伪影。
l 循环卷积模型(RCN)
基于卷积网络DenseNet和门控循环单位单元的集成,以利用帧之间的时间差异。

图5-2 RCN检测过程
检测分两步,预处理步骤包括检测、裁剪和对齐一系列帧上的面部,第二步通过结合卷积神经网络(CNN)和循环神经网络(RNN)来区分真假面部图像。
l 时间感知管线
强调深层视频包含帧内不一致和帧之间的时间不一致,使用CNN和长期短期记忆(LSTM)来检测Deepfake视频。
CNN用于提取帧级特征,并将其馈入LSTM以创建时间序列描述符。 之后,使用一个完全连接的网络根据序列描述符对真实视频中的篡改视频进行分类。
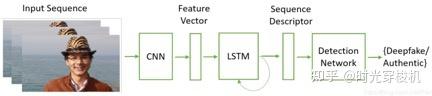
图5-3 基于时间感知管线检测过程
使用卷积神经网络(CNN)和长期短期记忆(LSTM)提取给定视频序列的时间特征(通过序列描述符表示)。 由全连接层组成的检测网络被用来作为序列描述符的输入,并计算属于真假帧序列的概率。
通常将视频分解为帧并探索单个帧内的视觉伪影以获得判别特征, 再将这些功能分配到深层或浅层分类器中以区分真假视频。根据分类器的类型(即深层或浅层)对方法分组。
l 深分类器(Deep classifiers)
Deepfake视频通常以有限的分辨率创建,需要仿射人脸变形方法(缩放、旋转、剪切)以匹配原始视频的配置(比如分辨率)。由于扭曲的面部区域和周围环境的分辨率不一致,此过程留下了CNN模型可检测到的伪影。
l 浅分类器(Shallow classifiers)
Deepfake检测方法主要依赖于伪造图像与真实图像或视频之间的固有特征的伪影或不一致。
由于Deepfake在人脸生成管道中存在缺陷,有通过观察3D头部姿势之间的差异(包括头部方向和位置)来检测,该方法基于中央面部区域的68个面部界标进行估算,检查3D头部姿势,提取的特征被馈送到SVM分类器中以获得检测结果。
有基于眼睛、牙齿和面部轮廓的视觉特征来检测伪影。视觉伪影是由于缺乏整体一致性,入射照明的错误或不精确估计或底层几何结构的不精确估计而引起的。
还有各种基于特定类型伪影的检测方法。
l 数据来源(Data Provenance)
为了预防深度伪造,有些建议使用分布式账本和区块链网络追踪多媒体数据源;相反,另一些建议利用以太坊智能合约像一个全局文件系统那样认证和管理内容。这些提议背后的假设是:一个内容只有在其来源可追溯时才被认为是真实的、可信的。
l 反击(Counter Attacks)
为了反击深度伪造,有些使用对抗性机器学习扰乱和破坏深度伪造网络的,比如添加严重的噪声扰动以阻止深度伪造正确的定位面部、使用对抗性噪声改变面部身份以使网络爬虫找不到目标训练图像而无法训练。
l 趋向研究身份不可知模型和高分辨率的深度伪造
(1)不成对的自监督训练技术以减少初始训练数据量;
(2)小样本学习以实现单张照片盗窃身份;
预先用大量数据集进行元训练(meta learning)获得小样本学习能力,通过元训练学习到怎样快速生成图像的能力,而不是具体生成某一特定类别图像的能力。
(3)通过AdaIN层、解耦和pix2pixHD网络组件改善面部质量和身份;
(4)通过时间判别器和光流预测提升视频的流畅度和逼真度;
(5)使用辅助网络以减轻边界伪影将合成物无缝融合到图像。
l 其它方面取得的重大进展
(1)在预训练的VGG人脸识别网络上使用感知损失
可显著提升面部质量,已应用在流行的在线deepfake工具。
(2)使用网络管道流水线
不是在单个网络上强制实施一组全局损失,而是使用网络管道,其中每个网络都承担着不同的责任(转换、生成、遮挡、混合等)以更好的控制最终输出,应对泛化性的挑战。
(3)实时深度伪造是一种趋势
一些研究以30fps实现实时伪造,但当前实时深度伪造的逼真度还很不够。
深度伪造攻击方和防御方相互博弈,大多数deepfake检测算法假定和对手是静态博弈,它们或专注于识别特定的伪影、或在应对新的和没见过的攻击时泛化性不足,最近随着伪造品质量的提升,表现很好的检测器正迅速减少。
l 攻击方避开基于伪影的检测
减轻单个缺陷以逃避伪影检测,比如添加判别器使得生成的生物信号受控、增加损失函数避免广泛的神经元激活使其覆盖范围最小化、重现整个头部或从相同的数据源中学习举止以逃避检测异常的姿势和举止、识别模糊内容的模型受噪声和GAN锐化影响、一些搜索人脸融合边界的模型不适用于经过图像修复或输出完整帧的改进的网络、将生成的伪造品传递给过滤器或执行物理复制或压缩以逃避取证搜索法(或至少提高错误报警率)。
l 攻击方避开深度学习分类器
使用对抗性学习添加扰动来逃避深度学习的检测,这些攻击会跨多个模型转移而无论所使用的训练数据,最近的进展表明这些攻击对未知的分类器和训练集也有效。
l 防御方主被动防御相结合
防御方暂时提供了适度的被动防御;深度伪造制作仍不完善,这些局限性提升了攻击的难度阈值,有时可能因为太耗时间和资源使得普通攻击者无法创建足够的伪造而逃避检测。
基于内容的防御对策是被动的、不可持续的,需要提供基于非内容的主动防御措施,比如建立在线视频内容来源和真实性的框架、应用对抗性机器学习来保护内容免遭篡改。
l 即将出现的威胁
(1)越来越多的伪造品会变成攻击个人或公司的货币化武器;
(2)深度伪造越来越实用和有效,实时深度伪造越来越逼真;
黑客组织将会利用深度伪造进行侦查作为APT(高级长期威胁)的一部分,国家级行为者通过重演官员或家庭成员进行间谍活动和破坏活动。
l 主动应对(保持领先)
(1)考虑攻击对手的下一步,而不只是当前攻击的弱点
评估这些攻击的理论极限,比如,找出模型延迟的边界以检测实时攻击、确定GAN的限制以设计适当的策略。
(2)探索当前deepfake检测器的弱点和局限性
通过识别和了解了这些漏洞,制定出更强大的对策。
l 技术层面
(1)理解制作和防范深度伪造的技术原理、优缺点有必要性。
(2)可作为AI技术在具体场景工程化综合运用的学习案例。
l 业务层面
(1)挑战:视觉深度伪造制作正逐渐成为多媒体创作的一种新形式,其潜在危害性值得关注;多媒体隐私数据的保护越来越值得重视,在网络上传播个人多媒体信息的潜在危害性越来越大。
(2)机遇:视觉AI技术在多媒体AI工具方向上有一定的探索尝试空间,比如表情包制作、虚拟人物制作等。
[1]Deepfake:https://en.wikipedia.org/wiki/Deepfake
[2]《The Creation and Detection of Deepfakes: A Survey》:
https://arxiv.org/pdf/2004.11138.pdf,2020.4.
https://zhuanlan.zhihu.com/p/139489768.
[3]《Deep Learning for Deepfakes Creation and Detection: A Survey》:
https://arxiv.org/abs/1909.11573,2019.9,
https://blog.csdn.net/Reddoge_/article/details/103822699.
[4]《DeepFaceLab: A simple, flexible and extensible face swapping framework》:https://arxiv.org/pdf/2005.05535.pdf,2020.5.
[5]《DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection》: https://arxiv.org/pdf/2001.00179.pdf,2020.1,
https://zhuanlan.zhihu.com/p/115070797,
https://zhuanlan.zhihu.com/p/92474937.
[6]《视听觉深度伪造检测技术研究综述》:http://jcs.iie.ac.cn/xxaqxb/ch/reader/create_pdf.aspx?file_no=20200202,2020.4.
[7]《从文本合成真实的唇语口型》:
https://www.jiqizhixin.com/articles/2018-01-14-5.
[8]《Buzzfeed Created a ‘Deepfake’ Obama PSA Video》:https://www.extremetech.com/extreme/267771-buzzfeed-created-a-deepfake-obama-psa-video,2018.4.
[9]《Lyrebird claims it can recreate any voice using just one minute of sample audio》:https://www.theverge.com/2017/4/24/15406882/ai-voice-synthesis-copy-human-speech-lyrebird,2017.4.
[10]《Realistic Deepfakes in 5 Minutes on Colab》:
https://towardsdatascience.com/realistic-deepfakes-colab-e13ef7b2bba7,2020.3.
[11]《Face2Face: Real-time Face Capture and Reenactment of RGB Videos》:http://niessnerlab.org/projects/thies2016face.html,2016.6.
[12]《Adobe is working on an audio app that lets you add words someone never said》:https://www.theverge.com/2016/11/3/13514088/adobe-photoshop-audio-project-voco,2016.11.
[13]《Family fun with deepfakes. Or how I got my wife onto the Tonight Show》:https://towardsdatascience.com/family-fun-with-deepfakes-or-how-i-got-my-wife-onto-the-tonight-show-a4454775c011,2018.2.
[14]《Lip-syncing Obama: New tools turn audio clips into realistic video》:https://www.washington.edu/news/2017/07/11/lip-syncing-obama-new-tools-turn-audio-clips-into-realistic-video/,2017.6.
[15]《Synthesizing Obama: Learning Lip Sync from Audio》: http://grail.cs.washington.edu/projects/AudioToObama/siggraph17_obama.pdf?_ga=2.261732173.1517641146.1606723485-1452069613.1606723485,2017.7.
[16]《Deepfake technology is changing fast - use these 5 resources to keep up》:https://journalistsresource.org/studies/society/deepfake-technology-5-resources/,2019.6.
[17]《Generative Adversarial Nets》:https://papers.nips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf,2014.6.
[18]《Everybody Dance Now》:
https://arxiv.org/pdf/1808.07371.pdf,2018.8.
[19]《A Style-Based Generator Architecture for Generative Adversarial Networks 1-2合集》:https://nvlabs.github.io/stylegan2/versions.html,2019.3.
[20]《Few-Shot Adversarial Learning of Realistic Neural Talking Head Models》:https://nvlabs.github.io/stylegan2/versions.html,2019.5.
https://blog.csdn.net/a312863063/article/details/90728818,2019.6.
https://cloud.tencent.com/developer/article/1477496,2019.7.
[21]《What Is a Deepfake?》:
https://www.pcmag.com/news/what-is-a-deepfake,2020.3.
[22]《Creating a dataset and a challenge for deepfakes》:
https://ai.facebook.com/blog/deepfake-detection-challenge/,2019.9.
[23]《深度伪造与检测技术综述》:http://www.jos.org.cn/jos/ch/reader/create_pdf.aspx?file_no=6140&journal_id=jos,2020.
[24]《DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection》:https://arxiv.org/pdf/2001.00179.pdf,2020.
[25]Visual artifact: https://en.wikipedia.org/wiki/Visual_artifact
[28]参见“杨幂朱茵‘换脸’了?变脸如此简单到底有多可怕”:https://www.sohu.com/a/299665489_105446.
[29]参见“私密空间偷拍,AI换脸?看看民法典人格权编如何回应”:https://www.thepaper.cn/newsDetail_forward_7708586.
[30]《Detect AI-generated Images & Deepfakes》:
https://jonathan-hui.medium.com/detect-ai-generated-images-deepfakes-part-1-b518ed5075f4,2020.
[31]《First Order Motion Model for Image Animation》:
https://proceedings.neurips.cc/paper/2019/hash/31c0b36aef265d9221af80872ceb62f9-Abstract.html,2019,
 上一篇
上一篇 




